说明
使用的操作系统为CentOS 7.6.1810,其他系统请自己根据差异做对应调整
仅用于记录部署过程
告警通知对接了邮件和钉钉机器人
安装
在监控告警系统主机上安装prometheus、alertmanager和grafana
被监控的主机安装各种各样的exporter,每个exporter只监控自身的服务状态
环境准备
1 | 创建prometheus配置目录 |
软件包
prometheus
1 | 下载解压 |
alertmanager
1 | 下载解压 |
node_exporter
1 | 下载解压 |
mysqld_exporter
1 | 下载解压 |
postgresql_exporter
1 | 下载解压 |
blackbox_exporter
1 | 下载解压 |
grafana
1 | 下载 |
配置
Prometheus
/etc/prometheus/prometheus.yml
1 | global: |
/etc/prometheus/rules.d/host-status.rules
1 | groups: |
/etc/prometheus/rules.d/mysql-status.rules
1 | groups: |
/etc/prometheus/rules.d/postgresql-status.rules
1 | groups: |
Alertmanager
/etc/prometheus/alertmanager.yml
1 | global: |
配置dingtalk webhook程序
1 | 这里偷懒用docker跑钉钉的webhook |
blackbox_exporter
/etc/prometheus/backbox_exporter.yml
1 | 没空搞,占个位 |
mysqld_exporter
需要创建用于监控的数据库用户
1 | CREATE USER 'prometheus'@'127.0.0.1' IDENTIFIED BY 'prometheus_password' WITH MAX_USER_CONNECTIONS 3; |
postgresql_exporter
根据需求决定是否使用superuser作为postgresql_exporter的数据库用户
如果要创建专用用户可以参照下面的方式创建用户
1 | # 创建postgresql_exporter专用用户 |
grafana
偷懒警告!这里定义管理员用户密码,还有secret_key,记得自己改,别瞎抄作业!
生产环境不要用默认密码,不然有你哭的时候
[security]
admin_user = admin
admin_password = admin
secret_key = SW2YcwTIb9zpOOhoPsMm
/etc/grafana/grafana.ini
1 | app_mode = production |
systemd服务
prometheus.service
/usr/lib/systemd/system/prometheus.service
1 | [Unit] |
alertmanager.servicce
/usr/lib/systemd/system/alertmanager.service
1 | [Unit] |
node_exporter.service
/usr/lib/systemd/system/node_exporter.service
1 | [Unit] |
blackbox_exporter.service
/usr/lib/systemd/system/balckbox_exporter.service
1 | [Unit] |
mysqld_exporter.service
/usr/lib/systemd/system/mysqld_exporter.service
1 | [Unit] |
postgresql_exporter.service
/usr/lib/systemd/system/postgresql_exporter.service
1 | [Unit] |
启动服务
修改了systemd脚本之后需要reload一下
1 | systemctl daemon-reload |
prometheus
1 | systemctl enable --now prometheus.service |
alertmanager
1 | systemctl enable --now alertmanager.service |
node_exporter
1 | systemctl enable --now node_exporter.service |
grafana
1 | systemctl enable --now grafana.service |
其他
其他服务同理,择需启动对应的服务即可
验证服务
prometheus
浏览器访问http://prometheus_server_ip:9090
alertmanager
浏览器访问http://prometheus_server_ip:9093
node_exporter
浏览器访问http://prometheus_server_ip:9100
grafana
浏览器访问http://prometheus_server_ip:3000
默认用户密码admin/admin,初次登录需要改密码
配置grafana监控面板
这里很多作业可以抄,这里简单列举几个我用到的面板
抄作业之前,先看看人家的说明!
node_exporter面板
1 Node Exporter 0.16–0.18 for Prometheus 监控展示看板

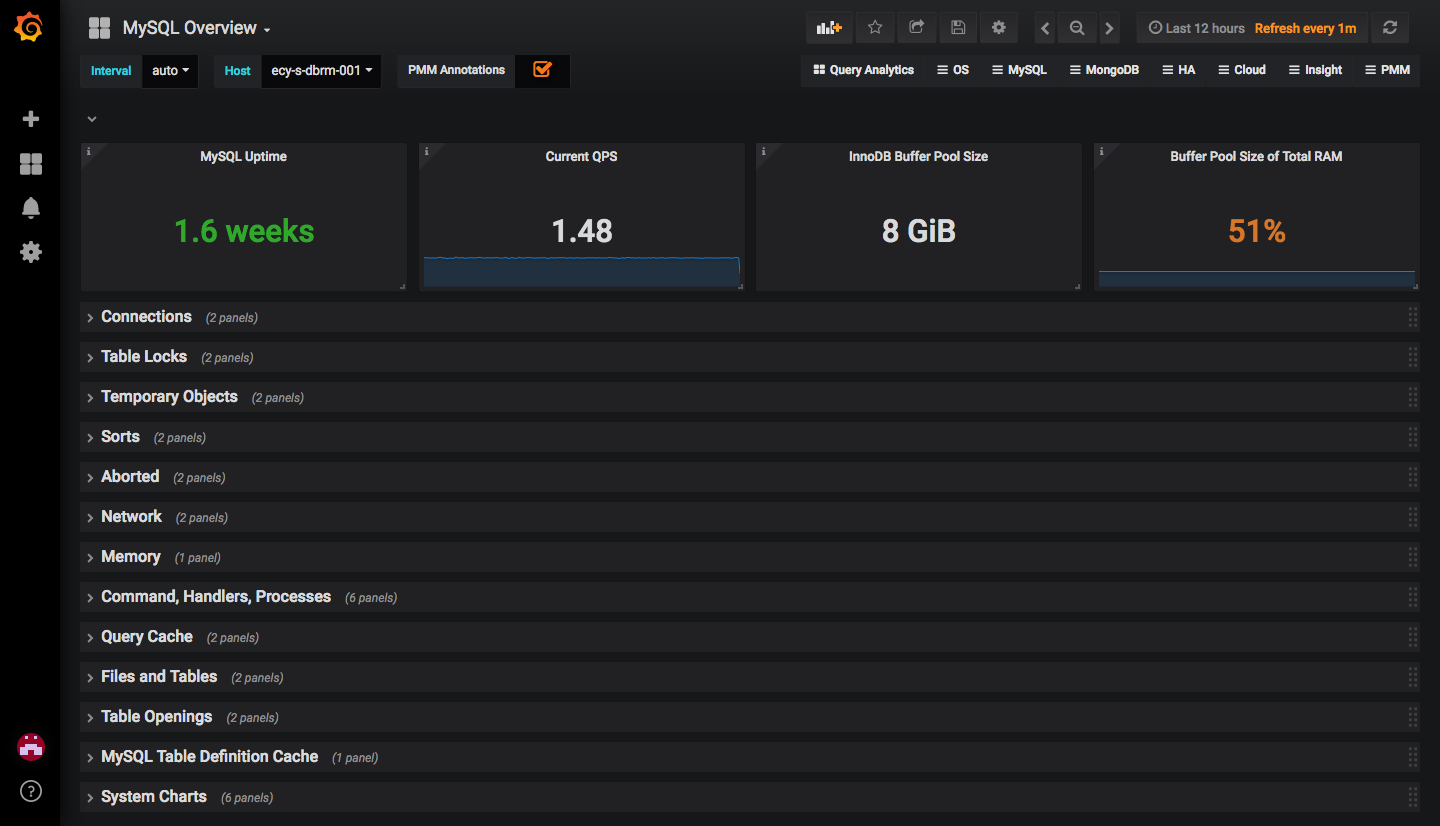
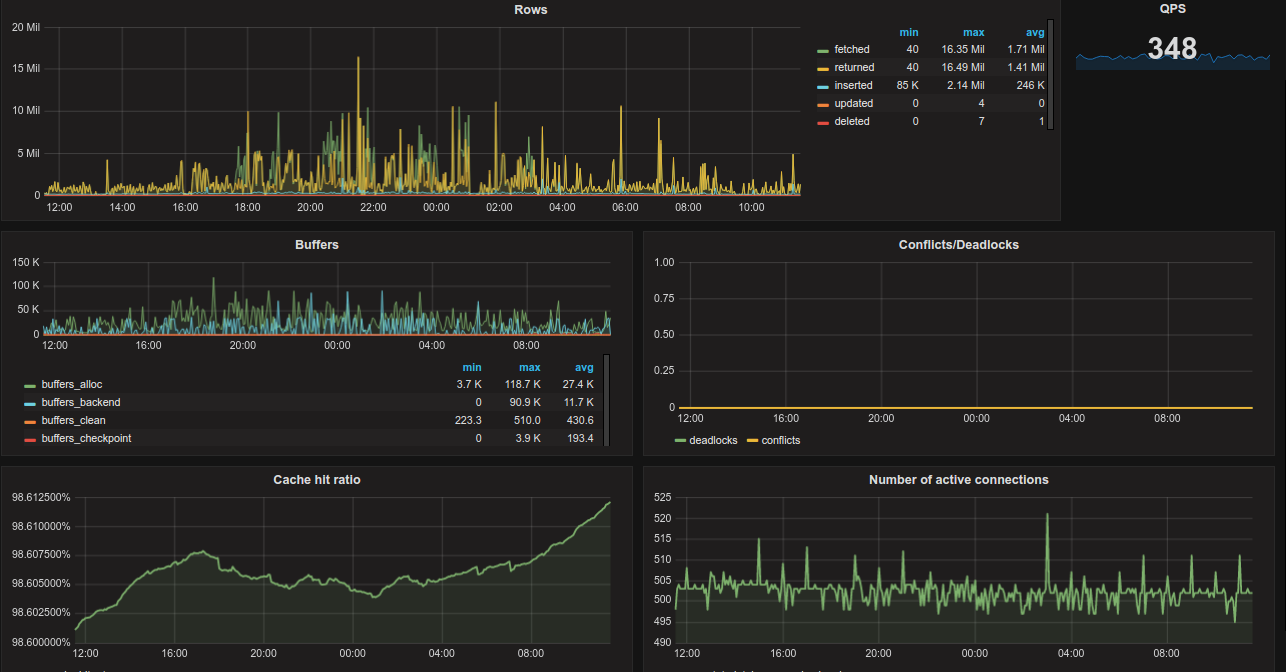
mysqld_exporter面板