说明
这里只记录搭建和简单测试过程
不保证
ctrl+c和ctrl+v能完整跑起来操作系统使用的
CentOS-7.6.1810 x86_64PostgreSQL版本号
10.8PGPool版本号
4.0.5虚拟机配置
1CPU 2G内存 20G系统盘
postgres用户默认情况下PGDATA变量是/var/lib/pgsql/10/data这里没有使用数据盘,有需要的可以自行调整!
由watchdog通过ARP协议提供的VIP切换来保证服务可用性,这里不涉及负载均衡!
注意!在某些公有云环境不一定支持基于ARP协议做VIP
架构图
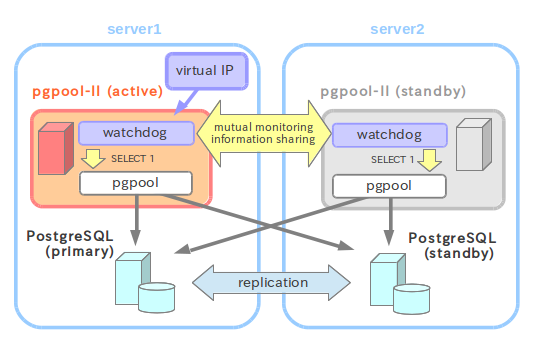
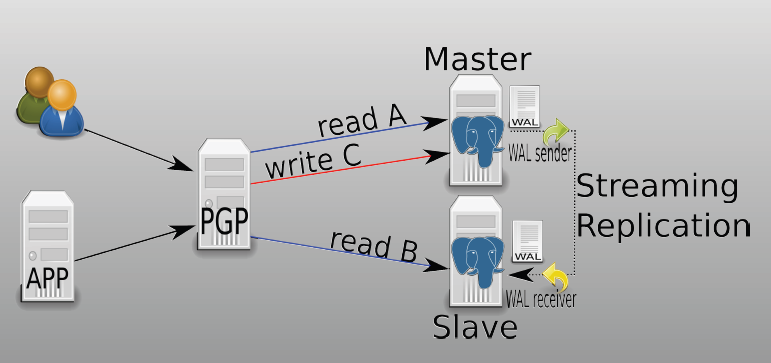
环境准备
主机清单
| 主机名 | IP地址 | 角色 | 监听端口 |
|---|---|---|---|
| vip | 172.16.80.200 | vip | |
| pg1 | 172.16.80.201 | master | 5432 |
| pg2 | 172.16.80.202 | slave | 5432 |
准备基于stream的主从集群
这里可以看这个链接PostgreSQL10基于stream复制搭建主从集群
修改hosts文件
把每个服务器的主机IP地址做静态解析
1 | 172.16.80.200 vip |
配置系统命令权限
切换脚本需要使用root权限运行
1 | chmod u+s /usr/sbin/ip /usr/sbin/arping |
配置SSH密钥
- 修改postgres用户的密码
1 | passwd postgres |
- 切换到postgres用户
1 | su - postgres |
- 生成SSH密钥
1 | ssh-keygen -t ecdsa -b 521 -N '' -f ~/.ssh/id_ecdsa |
- 配置SSH免密登录
1 | ssh-copy-id pg1 |
PGPool
创建PGPool健康检查用户
1 | create user pgpool_check with password 'pgpool_password'; |
安装PGPool
PGPool在PostgreSQL社区提供的YUM源里面有,直接装就是了
1 | yum install -y pgpool-II-10-4.0.5-1.rhel7 pgpool-II-10-extensions-4.0.5-1.rhel7 |
PGPool也提供了WebUI方便管理,按需安装
1 | yum install -y pgpoolAdmin |
配置PGPool
配置文件的目录在
/etc/pgpool-II-10
配置pcp.conf
pcp.conf是配置pgpool-II自己的用户名和密码
- 使用pg_md5命令加密密码
1 | pg_md5 pgpool_password |
- 输出示例
1 | 4aa0cb9673e84b06d4c8a848c80eb5d0 |
- 添加到
pcp.conf
1 | postgres:4aa0cb9673e84b06d4c8a848c80eb5d0 |
配置pool_hba.conf
pool_hba.conf跟PostgreSQL里面的pg_hba.conf作用一样,可以拷贝pg_hba.conf的内容过来
1 | TYPE DATABASE USER ADDRESS METHOD |
配置pgpool.conf
pgpool.conf可以参考/etc/pgpool-II-10/pgpool.conf.sample的配置需要注意的几个点!
master节点
1 | ---------------------------- |
slave节点
可以照抄master节点的配置
注意以下几个地方要做对应变更
1 | wd_hostname = 'pg2' |
生成pool_passwd文件
在
/etc/pgpool-II-10/pool_passwd添加连接到后端PostgreSQL数据库的用户密码会提示输入密码,这里的密码请填写PostgreSQL数据库用户对应的密码
1 | pg_md5 -p -m -u postgres pool_passwd |
修改权限
1 | chmod a+r /etc/pgpool-II-10/pool_passwd |
创建切换脚本
/etc/pgpool-II-10/failover_stream.sh
1 | !/bin/bash |
增加执行权限
1 | chmod a+rx /etc/pgpool-II-10/failover_stream.sh |
启动PGPool
1 | systemctl enable pgpool-II-10.service |
验证PGPool
- 使用psql连接PGPool
1 | psql -U postgres -h vip -p 9999 |
- 查看PGPool节点
1 | postgres=# show pool_nodes; |
PGPool节点重启
- 查看watchdog的VIP所在主机
1 | ip address |
- 重启前查看PGPool节点信息
1 | postgres=# show pool_nodes; |
- 登录VIP所在主机直接重启
1 | reboot |
- 再次查看节点信息
可以看到VIP所在主机重启之后
SQL连接会提示连接不可用
在watchdog的作用下,VIP会自动切换到另一个PGPool节点
SQL连接再次重新连接成功!
1 | postgres=# show pool_nodes; |
PGPool进程被杀
- 查看watchdog的VIP所在主机
1 | ip address |
- 查看PGPool节点信息
1 | postgres=# \x |
- 找PGPool的进程
1 | ps -ef | grep pgpool |
- 杀PGPool进程
1 | kill -9 12641 |
- PGPool进程日志
可以看到PGPool的watchdog几乎立刻就反应过来了
1 | May 26 20:53:14 pg2 pgpool[9607]: LOG: watchdog node state changed from [STANDBY] to [JOINING] |
模拟master节点宕机
- 查看节点信息
1 | postgres=# show pool_nodes; |
- master节点直接关机
1 | shutdown -h now |
- 查看PGPool日志
1 | May 26 21:06:02 pg2 pgpool[10800]: 2019-05-26 21:06:02 PID=10801 USER=[No Connection] DB=[No Connection]: LOG: new IPC connection received |
- 查看PGPool节点
可以看到PGPool帮我们自动将standby节点切换为primary
1 | postgres=# show pool_nodes; |
启动master节点
在master登录到自己的PostgreSQL
1 | psql -U postgres |
- 查看
pg_is_in_recovery()
发现master节点上面的PostgreSQL状态为
f,没有自动转换为pg2的从库
1 | postgres=# select pg_is_in_recovery(); |
- 手动处理一下
切换用户
1 | su - postgres |
创建
recovery.conf文件
1 | 指定timeline为latest,保证主从数据差异尽可能小 |
重启PostgreSQL
1 | pg_ctl restart |
登录数据库查看状态,可以看到状态变成了
t
1 | postgres=# select pg_is_in_recovery(); |
手动加入PGPool集群
这里输入之前
pcp.conf定义的用户密码
- 参数解析如下
-h这里指定pcp的IP地址,这里用VIP-p这里指定pcp的端口,默认是9898-U这里指定登录pcp的用户,在/etc/pgpool-II-10/pcp.conf里面定义的-n这里指定节点ID,可以在show pool_nodes里面查到节点对应的ID号-d输出debug日志
1 | pcp_attach_node -U postgres -h vip -p 9898 -n 0 -d |
查看PGPool节点状态,可以看到pg1状态是waiting,过一阵之后就变成up了
1 | postgres=# show pool_nodes; |
维护操作
PGPool节点down
- 检查PostgreSQL是否正常启动
- 查看
$PGDATA目录是否有recovery.conf或者recovery.done,一般情况下,只存在一个文件- 其中
recovery.done会让数据库启动时以主库形式启动 recovery.conf会让数据库作为从库启动- 在发生主从切换的时候,
recovery.conf会被重命名为recovery.done
- 其中
- 如确认当前down节点是要作为从库启动,则重命名
recovery.done为recovery.conf,然后重启数据库- 需要确认一下是否能从新的主库同步数据
PGPool节点waiting
- 节点还在做主从同步
- PGPool还在创建子进程用于连接此节点,子进程数量多,耗时会相应变长
- 如果登录很久都是waiting,可以尝试重启一下PGPool的服务
PGPool重新添加节点
确保主从数据库都已正常,但是节点状态还是down,就需要手工添加到集群中了
- 使用
pcp_attach_node命令,输入pcp.conf定义的密码之后即可将节点重新加入PGPool - 参数解析如下
-h这里指定pcp的IP地址,这里用VIP-p这里指定pcp的端口,默认是9898-U这里指定登录pcp的用户,在/etc/pgpool-II-10/pcp.conf里面定义的-n这里指定节点ID,可以在show pool_nodes里面查到节点对应的ID号-d输出debug日志
1 | pcp_attach_node -h vip -p 9898 -U postgres -n NODE_ID -d |