介绍
- 只记录部署过程,不保证
ctrl+c和ctrl+v能直接跑!请自行判断参数是否能直接套用! - Kubernetes-v1.15已经在
2019-06-19发布,而Kubernetes-v1.14作为上一个release版本已经更新到了1.14.3。 - 之前写的Kubernetes-v1.11的高可用集群部署文档由于版本变迁部分参数需要改动,部署过程有些地方欠缺考虑,这里以Kubernetes-v1.14.3版本重新做一次文档整理
- 因此文章整体架构基本与【二进制部署 kubernetes v1.11.x 高可用集群】相同
- 配置部分参考kubeadm的参数
部署说明
本次部署方式为二进制可执行文件的方式部署
- 注意请根据自己的实际情况调整
- 对于生产环境部署,请注意某些参数的选择
如无特殊说明,均在k8s-m1节点上执行
参考博文
感谢两位大佬的文章,这里整合一下两位大佬的内容,结合自己的理解整理本文
- 漠然大佬的【Kubernetes 1.13.4 搭建】
- 张馆长的【二进制部署Kubernetes v1.13.5 HA可选】
软件版本
这里参考
kubeadm-1.14的镜像版本和yum源依赖
- Kubernetes版本
v1.14.3 - Docker-CE版本
18.09.06 - CNI-Plugins版本
v0.75 - etcd版本
v3.2.24
网络信息
- 基于CNI的模式实现容器网络
- Cluster IP CIDR:
10.244.0.0/16 - Service Cluster IP CIDR:
10.96.0.0/12 - Service DNS IP:
10.96.0.10 - Kubernetes API VIP:
172.16.80.200
节点信息
- 操作系统可采用
Ubuntu Server 16.04 LTS、Ubuntu Server 18.04 LTS和CentOS 7.6 - 由
keepalived提供VIP - 由
haproxy提供kube-apiserver四层负载均衡 - 通过污点的方式防止工作负载被调度到master节点
- 服务器配置请根据实际情况适当调整
| IP地址 | 主机名 | 操作系统 | 内核版本 | 角色 | CPU | 内存 |
|---|---|---|---|---|---|---|
| 172.16.80.201 | k8s-m1 | CentOS-7.6.1810 | 3.10.0-957 | master+node | 4 | 8G |
| 172.16.80.202 | k8s-m2 | CentOS-7.6.1810 | 3.10.0-957 | master+node | 4 | 8G |
| 172.16.80.203 | k8s-m3 | CentOS-7.6.1810 | 3.10.0-957 | master+node | 4 | 8G |
| 172.16.80.204 | k8s-n1 | CentOS-7.6.1810 | 3.10.0-957 | node | 4 | 8G |
| 172.16.80.205 | k8s-n2 | CentOS-7.6.1810 | 3.10.0-957 | node | 4 | 8G |
目录说明
- /usr/local/bin/:存放kubernetes和etcd二进制文件
- /opt/cni/bin/: 存放cni-plugin二进制文件
- /etc/etcd/:存放etcd配置文件和SSL证书
- /etc/kubernetes/:存放kubernetes配置和SSL证书
- /etc/cni/net.d/:安装CNI插件后会在这里生成配置文件
- $HOME/.kube/:kubectl命令会在家目录下建立此目录,用于保存访问kubernetes集群的配置和缓存
- $HOME/.helm/:helm命令会建立此目录,用于保存helm缓存和repository信息
事前准备
事情准备在所有服务器上都需要完成
部署过程以
root用户完成- 所有服务器
网络互通,k8s-m1可以通过SSH证书免密登录到其他master节点,用于分发文件
编辑hosts文件
1 | cat > /etc/hosts <<EOF |
时间同步服务
集群系统需要各节点时间同步
参考链接:RHEL7官方文档
这里使用公网对时,如果需要内网对时,请自行配置
1 | yum install -y chrony |
关闭firewalld
1 | systemctl stop firewalld |
关闭无用服务
请根据自己的环境针对性地关闭服务
1 | 禁用蓝牙 |
关闭SELINUX
1 | setenforce 0 |
禁用swap
1 | swapoff -a && sysctl -w vm.swappiness=0 |
配置sysctl参数
1 | cat > /etc/sysctl.d/99-centos.conf <<EOF |
更新软件包
1 | yum update -y |
安装软件包
1 | yum groups install base -y |
配置开机加载ipvs模块
1 | cat > /etc/modules-load.d/ipvs.conf <<EOF |
安装docker-ce
1 | 删除旧版本docker |
配置docker-ce
CentOS/RHEL 7.4+
1 | mkdir -p /etc/docker |
Ubuntu 16.04
1 | mkdir -p /etc/docker |
配置docker命令补全
1 | cp /usr/share/bash-completion/completions/docker /etc/bash_completion.d/ |
配置docker服务开机自启动
1 | systemctl enable docker.service |
查看docker信息
1 | docker info |
禁用docker源
为避免yum update时更新docker,将docker源禁用
1 | yum-config-manager --disable docker-ce-stable |
确保以最新的内核启动系统
1 | reboot |
定义集群变量
注意- 这里的变量只对当前会话生效,如果会话断开或者重启服务器,都需要重新定义变量
HostArray定义集群中所有节点的主机名和IPMasterArray定义master节点的主机名和IPNodeArray定义node节点的主机名和IP,这里master也运行kubelet所以也需要加入到NodeArrayVIP_IFACE定义keepalived的VIP绑定在哪一个网卡ETCD_SERVERS以MasterArray的信息生成etcd集群服务器列表ETCD_INITIAL_CLUSTER以MasterArray信息生成etcd集群初始化列表POD_DNS_SERVER_IP定义Pod的DNS服务器IP地址
1 | declare -A HostArray MasterArray NodeArray |
下载所需软件包
创建工作目录
1 | mkdir -p /root/software |
下载解压软件包
kubernetes
1 | echo "--- 下载kubernetes ${KUBERNETES_VERSION} 二进制包 ---" |
etcd
1 | 下载etcd二进制包 |
CNI-Plugin
1 | 下载CNI-plugin |
生成集群Certificates
说明
本次部署,需要为etcd-server、etcd-client、kube-apiserver、kube-controller-manager、kube-scheduler、kube-proxy生成证书。另外还需要生成sa、front-proxy-ca、front-proxy-client证书用于集群的其他功能。
- 要注意CA JSON文件的
CN(Common Name)与O(Organization)等内容是会影响Kubernetes组件认证的。CNCommon Name,kube-apiserver会从证书中提取该字段作为请求的用户名(User Name)OOragnization,kube-apiserver会从证书中提取该字段作为请求用户的所属组(Group)
- CA是自签名根证书,用来给后续各种证书签名
- kubernetes集群的所有状态信息都保存在etcd中,kubernetes组件会通过kube-apiserver读写etcd里面的信息
- etcd如果暴露在公网且没做SSL/TLS验证,那么任何人都能读写数据,那么很可能会无端端在kubernetes集群里面多了挖坑Pod或者肉鸡Pod
- 本文使用
CFSSL创建证书,证书有效期10年 - 建立证书过程在k8s-m1上完成
- 用于生成证书的JSON文件已经打包好在这里pki.zip
下载CFSSL工具
1 | wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -O /usr/local/bin/cfssl-certinfo |
创建工作目录
1 | mkdir -p /root/pki /root/master /root/node |
创建用于生成证书的json文件
ca-config.json
1 | cat > ca-config.json <<EOF |
ca-csr.json
1 | cat > ca-csr.json <<EOF |
etcd-ca-csr.json
1 | cat > etcd-ca-csr.json <<EOF |
etcd-server-csr.json
1 | cat > etcd-server-csr.json <<EOF |
etcd-client-csr.json
1 | cat > etcd-client-csr.json <<EOF |
kube-apiserver-csr.json
1 | cat > kube-apiserver-csr.json <<EOF |
kube-manager-csr.json
1 | cat > kube-manager-csr.json <<EOF |
kube-scheduler-csr.json
1 | cat > kube-scheduler-csr.json <<EOF |
kube-proxy-csr.json
1 | cat > kube-proxy-csr.json <<EOF |
kube-admin-csr.json
1 | cat > kube-admin-csr.json <<EOF |
front-proxy-ca-csr.json
1 | cat > front-proxy-ca-csr.json <<EOF |
front-proxy-client-csr.json
1 | cat > front-proxy-client-csr.json <<EOF |
sa-csr.json
1 | cat > sa-csr.json <<EOF |
创建etcd证书
etcd-ca证书
1 | echo '--- 创建etcd-ca证书 ---' |
etcd-server证书
1 | echo '--- 创建etcd-server证书 ---' |
etcd-client证书
1 | echo '--- 创建etcd-client证书 ---' |
创建kubernetes证书
kubernetes-CA 证书
1 | echo '--- 创建kubernetes-ca证书 ---' |
kube-apiserver证书
1 | echo '--- 创建kube-apiserver证书 ---' |
kube-controller-manager证书
1 | echo '--- 创建kube-controller-manager证书 ---' |
kube-scheduler证书
1 | echo '--- 创建kube-scheduler证书 ---' |
kube-proxy证书
1 | echo '--- 创建kube-proxy证书 ---' |
kube-admin证书
1 | echo '--- 创建kube-admin证书 ---' |
Front Proxy证书
1 | echo '--- 创建Front Proxy Certificate证书 ---' |
Service Account证书
1 | echo '--- 创建service account证书 ---' |
bootstrap-token
1 | 生成 Bootstrap Token |
encryption.yaml
1 | ENCRYPTION_TOKEN=$(head -c 32 /dev/urandom | base64) |
audit-policy.yaml
这里使用最低限度的审计策略文件
1 | echo '--- 创建创建高级审计配置 ---' |
创建kubeconfig文件
说明
- kubeconfig 文件用于组织关于集群、用户、命名空间和认证机制的信息。
- 命令行工具
kubectl从 kubeconfig 文件中得到它要选择的集群以及跟集群 API server 交互的信息。 - 默认情况下,
kubectl会从$HOME/.kube目录下查找文件名为config的文件。
注意: 用于配置集群访问信息的文件叫作
kubeconfig文件,这是一种引用配置文件的通用方式,并不是说它的文件名就是kubeconfig。
Components kubeconfig
1 | for TARGET in kube-controller-manager kube-scheduler kube-admin; do |
Bootstrap kubeconfig
1 | 设置集群参数 |
清理证书CSR文件
1 | echo '--- 删除*.csr文件 ---' |
修改文件权限
1 | chown root:root *pem *kubeconfig *yaml |
Etcd Cluster
说明
- Kubernetes集群数据需要存放在etcd中
- etcd集群部署在master节点上
- 部署三节点的etcd cluster
- etcd集群启用基于TLS的客户端身份验证+集群节点身份认证
准备环境
查看集群部署的环境变量
这里主要检查上面集群变量定义的时候,是否有遗漏或者不正确
1 | echo "ETCD_SERVERS=${ETCD_SERVERS}" |
添加用户
etcd以普通用户运行
1 | echo '--- master节点添加etcd用户 ---' |
创建目录
1 | echo '--- master节点创建目录 ---' |
创建工作目录
1 | mkdir -p /root/master |
切换工作目录
1 | cd /root/master |
部署etcd
创建systemd服务脚本
1 | cat > etcd.service <<EOF |
创建etcd配置模板
1 | cat > etcd.config.yaml.example <<EOF |
分发etcd集群文件
1 | for NODE in "${!MasterArray[@]}";do |
启动etcd cluster
- etcd 进程首次启动时会等待其它节点的 etcd 加入集群,命令 systemctl start etcd 会卡住一段时间,为正常现象
- 启动之后可以通过
etcdctl命令查看集群状态
1 | for NODE in "${!MasterArray[@]}";do |
- 为方便维护,可使用alias简化etcdctl命令
1 | cat >> /root/.bashrc <<EOF |
验证etcd集群状态
- etcd提供v2和v3两套API
- kubernetes使用的是etcd v3 API
应用环境变量
应用上面定义的alias
1 | source /root/.bashrc |
使用v2 API访问集群
获取集群状态
1 | etcdctl2 cluster-health |
示例输出
1 | member 222fd3b0bb4a5931 is healthy: got healthy result from https://172.16.80.203:2379 |
获取成员列表
1 | etcdctl2 member list |
示例输出
1 | 222fd3b0bb4a5931: name=k8s-m3 peerURLs=https://172.16.80.203:2380 clientURLs=https://172.16.80.203:2379 isLeader=false |
使用v3 API访问集群
获取集群endpoint状态
1 | etcdctl3 endpoint health |
示例输出
1 | https://172.16.80.201:2379 is healthy: successfully committed proposal: took = 2.879402ms |
获取集群成员列表
1 | etcdctl3 member list --write-out=table |
示例输出
1 | +------------------+---------+--------+----------------------------+----------------------------+ |
配置定时备份脚本
1 | !/bin/sh |
Kubernetes Masters
Keepalived和HAProxy
说明
HAProxy
- 提供多个 API Server 的负载均衡(Load Balance)
- 监听VIP的
8443端口负载均衡到三台master节点的6443端口
Keepalived
- 提供虚拟IP位址(VIP),来让vip落在可用的master主机上供所有组件访问master节点
- 提供健康检查脚本用于切换VIP
切换工作目录
1 | cd /root/master |
安装Keepalived和HAProxy
1 | for NODE in "${!MasterArray[@]}";do |
Keepalived
创建配置模板
1 | cat > keepalived.conf.example <<EOF |
生成配置文件
通过集群变量替换配置模板的字符串,然后重定向到新的配置文件
1 | sed -r -e "s#\{\{ VIP \}\}#${VIP}#" \ |
创建keepalived服务检查脚本
1 | cat > check_haproxy.sh <<EOF |
HAproxy
创建配置模板
1 | cat > haproxy.cfg.example <<EOF |
生成配置文件
通过集群变量替换配置模板的字符串,然后重定向到新的配置文件
1 | sed -e '$r '<(paste <( seq -f' server k8s-api-%g' ${#MasterArray[@]} ) <( xargs -n1<<<${MasterArray[@]} | sort | sed 's#$#:6443 check#')) haproxy.cfg.example > haproxy.cfg |
分发配置文件
1 | for NODE in "${!MasterArray[@]}";do |
启动keepalived和HAProxy服务
1 | for NODE in "${!MasterArray[@]}";do |
验证服务状态
- 需要大约十秒的时间等待keepalived和haproxy服务起来
- 这里由于后端的kube-apiserver服务还没启动,只测试是否能ping通VIP
- 如果VIP没起来,就要去确认一下各master节点的keepalived服务是否正常
1 | sleep 15 && ping -c 4 $VIP |
Kubernetes Master服务
切换工作目录
1 | cd /root/master |
添加用户
1 | echo '--- master节点添加用户 ---' |
创建程序运行目录
1 | echo '--- master节点创建目录 ---' |
kube-apiserver
说明
- 以 REST APIs 提供 Kubernetes 资源的 CRUD,如授权、认证、存取控制与 API 注册等机制。
- 关闭默认非安全端口8080,在安全端口 6443 接收 https 请求
- 严格的认证和授权策略 (x509、token、RBAC)
- 开启 bootstrap token 认证,支持 kubelet TLS bootstrapping
- 使用 https 访问 kubelet、etcd,加密通信
配置参数
--allow-privileged=true启用容器特权模式--apiserver-count=3指定集群运行模式,其它节点处于阻塞状态--audit-policy-file=/etc/kubernetes/audit-policy.yaml基于audit-policy.yaml文件定义的内容启动审计功能--authorization-mode=Node,RBAC开启 Node 和 RBAC 授权模式,拒绝未授权的请求--disable-admission-plugins=和--enable-admission-plugins禁用和启用准入控制插件。准入控制插件会在请求通过认证和授权之后、对象被持久化之前拦截到达apiserver的请求。
准入控制插件依次执行,因此需要注意顺序。
如果插件序列中任何一个拒绝了请求,则整个请求将立刻被拒绝并返回错误给客户端。
关于admission-plugins官方文档里面有推荐配置,这里直接采用官方配置。
注意针对不同kubernetes版本都会有不一样的配置,具体可以看这里。
官方说明: For Kubernetes version 1.10 and later, the recommended admission controllers are enabled by default.
--enable-bootstrap-token-auth=true启用 kubelet bootstrap 的 token 认证--experimental-encryption-provider-config=/etc/kubernetes/encryption.yaml启用加密特性将Secret数据加密存储到etcd--insecure-port=0关闭监听非安全端口8080--runtime-config=api/all=true启用所有版本的 APIs--service-cluster-ip-range=10.96.0.0/12指定 Service Cluster IP 地址段--service-node-port-range=30000-32767指定 NodePort 的端口范围--target-ram-mb配置缓存大小,参考值为节点数*60--event-ttl配置kubernets events的保留时间,默认1h0m0s
创建配置模板
1 | cat > kube-apiserver.conf.example <<EOF |
创建systemd服务脚本
1 | cat > kube-apiserver.service <<EOF |
kube-controller-manager
说明
- 通过核心控制循环(Core Control Loop)监听 Kubernetes API
的资源来维护集群的状态,这些资源会被不同的控制器所管理,如 Replication Controller、Namespace
Controller 等等。而这些控制器会处理着自动扩展、滚动更新等等功能。 - 关闭非安全端口,在安全端口 10252 接收 https 请求
- 使用 kubeconfig 访问 kube-apiserver 的安全端口
配置参数
--allocate-node-cidrs=true在cloud provider上分配和设置pod的CIDR--cluster-cidr集群内的pod的CIDR范围,需要--allocate-node-cidrs设为true--experimental-cluster-signing-duration=8670h0m0s指定 TLS Bootstrap 证书的有效期--feature-gates=RotateKubeletServerCertificate=true开启 kublet server 证书的自动更新特性--horizontal-pod-autoscaler-use-rest-clients=true能够使用自定义资源(Custom Metrics)进行自动水平扩展--leader-elect=true集群运行模式,启用选举功能,被选为 leader 的节点负责处理工作,其它节点为阻塞状态--node-cidr-mask-size=24集群中node cidr的掩码--service-cluster-ip-range=10.96.0.0/16指定 Service Cluster IP 网段,必须和 kube-apiserver 中的同名参数一致--terminated-pod-gc-thresholdexit状态的pod超过多少会触发gc
创建配置文件
1 | cat > kube-controller-manager.conf <<EOF |
创建systemd服务脚本
1 | cat > kube-controller-manager.service <<EOF |
kube-scheduler
说明
- 负责将一个(或多个)容器依据调度策略分配到对应节点上让容器引擎(如 Docker)执行。
- 调度受到 QoS 要求、软硬性约束、亲和性(Affinity)等等因素影响。
配置参数
--algorithm-provider=DefaultProvider使用默认调度算法--leader-elect=true集群运行模式,启用选举功能,被选为 leader 的节点负责处理工作,其它节点为阻塞状态
创建配置文件
1 | cat > kube-scheduler.conf <<EOF |
创建systemd服务脚本
1 | cat > kube-scheduler.service <<EOF |
分发配置文件
1 | for NODE in "${!MasterArray[@]}";do |
分发master组件二进制文件
1 | echo '--- 分发kubernetes和etcd二进制文件 ---' |
启动Kubernetes master服务
1 | for NODE in "${!MasterArray[@]}";do |
验证Kubernetes集群服务
检查集群components状态
1 | kubectl --kubeconfig=/etc/kubernetes/kube-admin.kubeconfig get cs |
输出示例
1 | NAME STATUS MESSAGE ERROR |
检查集群endpoints状态
1 | kubectl --kubeconfig=/etc/kubernetes/kube-admin.kubeconfig get endpoints |
输出示例
1 | NAME ENDPOINTS AGE |
查看ETCD的数据
Kubernetes集群数据会写入到etcd,这里检查一下是否能正常写入到etcd
检查方式,查看etcd里面的key
1 | export ETCDCTL_API=3 |
输出示例
1 | /registry/apiregistration.k8s.io/apiservices/v1. |
配置kubectl
集群配置文件
kubectl默认会加载
~/.kube/config文件,作为默认连接Kubernetes集群的凭证
1 | for NODE in "${!MasterArray[@]}";do |
kubectl命令补齐
临时生效
1 | source <(kubectl completion bash) |
开机自动加载
1 | for NODE in "${!MasterArray[@]}";do |
配置TLS Bootstrap
- 当集群开启了 TLS 认证后,每个节点的 kubelet 组件都要使用由 apiserver 使用的 CA 签发的有效证书才能与
apiserver 通讯 - 如果节点多起来,为每个节点单独签署证书将是一件非常繁琐的事情
- TLS bootstrapping 功能就是让 kubelet 先使用一个预定的低权限用户连接到 apiserver,然后向 apiserver 申请证书,kubelet 的证书由 apiserver 动态签署;
创建工作目录
1 | mkdir -p /root/yaml/ |
创建TLS Bootstrap Token对象
1 | kubectl -n kube-system create secret generic bootstrap-token-${BOOTSTRAP_TOKEN_ID} \ |
创建YAML文件
1 | cat > /root/yaml/kubelet-tls-bootstrap-rbac.yaml <<EOF |
创建RBAC规则
1 | kubectl apply -f /root/yaml/kubelet-tls-bootstrap-rbac.yaml |
kube-apiserver获取node信息的权限
说明
本文部署的kubelet关闭了匿名访问,因此需要额外为kube-apiserver添加权限用于访问kubelet的信息
若没添加此RBAC,则kubectl在执行logs、exec等指令的时候会提示401 Forbidden
1 | kubectl -n kube-system logs calico-node-pc8lq |
参考文档:Kubelet的认证授权
创建YAML文件
1 | cat > /root/yaml/apiserver-to-kubelet-rbac.yaml <<EOF |
创建RBAC规则
1 | kubectl apply -f /root/yaml/apiserver-to-kubelet-rbac.yaml |
Kubernetes Nodes
说明
节点配置
- 安装Docker-ce,配置与master节点一致即可
- 安装cni-plugins、kubelet、kube-proxy
- 关闭防火墙和SELINUX
kubelet运行需要root权限- 这里是以k8s-m1、k8s-m2、k8s-m3、k8s-n1、k8s-n2作为Work节点加入集群
kubelet
- 管理容器生命周期、节点状态监控
- 目前 kubelet 支持三种数据源来获取节点Pod信息:
- 本地文件
- 通过 url 从网络上某个地址来获取信息
- API Server:从 kubernetes master 节点获取信息
- 使用kubeconfig与kube-apiserver通信
- 这里启用
TLS-Bootstrap实现kubelet证书动态签署证书,并自动生成kubeconfig
kube-proxy
- Kube-proxy是实现Service的关键插件,kube-proxy会在每台节点上执行,然后监听API Server的Service与Endpoint资源物件的改变,然后来依据变化调用相应的组件来实现网路的转发
- kube-proxy可以使用
userspace(基本已废弃)、iptables(默认方式)和ipvs来实现数据报文的转发 - 这里使用的是性能更好、适合大规模使用的
ipvs - 以DaemonSet方式运行
kubelet配置
说明
- kubelet在
1.10版本开始动态配置特性进入Beta阶段,因此绝大部分配置被标记为DEPRECATED,官方推荐使用--config指定配置文件,并在配置文件里面指定原来命令行中配置的内容。 - 因此kubelet的配置实际被分割成两个部分,启动参数和动态配置参数
创建目录
1 | mkdir -p /root/node |
切换工作目录
1 | cd /root/node |
配置文件
1 | cat > kubelet.config <<EOF |
systemd服务脚本
--bootstrap-kubeconfig=/etc/kubernetes/bootstrap.kubeconfig指定bootstrap启动时使用的kubeconfig--network-plugin=cni定义网络插件,Pod生命周期使用此网络插件--node-labels=node-role.kubernetes.io/node=''kubelet注册当前Node时设置的Label,以key=value的格式表示,多个labe以逗号分隔--pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.1Pod的pause镜像
1 | cat > kubelet.service <<EOF |
创建程序目录
1 | for NODE in "${!HostArray[@]}";do |
分发文件
1 | for NODE in "${!HostArray[@]}";do |
启动kubelet服务
1 | for NODE in "${!HostArray[@]}";do |
获取集群节点信息
- 此时由于未按照网络插件,所以节点状态为
NotReady
1 | kubectl get node -o wide |
输出示例
1 | NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME |
节点标签
master节点
- 声明污点,避免没有声明容忍该污点的Pod被调度到master节点
1 | kubectl label node ${!MasterArray[@]} node-role.kubernetes.io/master="" |
node节点
1 | kubectl label nodes ${!NodeArray[@]} node-role.kubernetes.io/node="" |
Kubernetes Core Addons
Kube-Proxy
说明
- Kube-proxy是实现Service的关键插件,kube-proxy会在每台节点上执行,然后监听API
Server的Service与Endpoint资源物件的改变,然后来依据变化执行iptables来实现网路的转发。 - 本文使用DaemonSet来运行Kube-Proxy组件。
创建工作目录
1 | mkdir -p /root/yaml/CoreAddons/kube-proxy |
切换工作目录
1 | cd /root/yaml/CoreAddons/kube-proxy |
创建YAML文件
ServicAccount
1 | cat > /root/yaml/CoreAddons/kube-proxy/kube-proxy-sa.yaml <<EOF |
ConfigMap
1 | cat > /root/yaml/CoreAddons/kube-proxy/kube-proxy-cm.yaml <<EOF |
DaemonSet
1 | cat > /root/yaml/CoreAddons/kube-proxy/kube-proxy-ds.yaml <<EOF |
ClusterRoleBinding
1 | cat > /root/yaml/CoreAddons/kube-proxy/kube-proxy-rbac.yaml <<EOF |
部署Kube-Proxy
1 | kubectl apply -f /root/yaml/CoreAddons/kube-proxy/ |
验证Kube-Proxy
查看Pod
1 | kubectl -n kube-system get pod -l k8s-app=kube-proxy |
查看IPVS规则
1 | ipvsadm -ln |
查看Kube-Proxy代理模式
1 | curl localhost:10249/proxyMode |
网络插件
说明
- 只要符合CNI规范的网络组件都可以给kubernetes使用
- 网络组件清单可以在这里看到Network Plugins
- 这里只列举
kube-flannel和calico,flannel和calico的区别可以自己去找资料 - 网络组件只能选一个来部署
- 本文使用
kube-flannel部署网络组件,calico已测试可用 - 在k8s-m1上操作
创建工作目录
1 | mkdir -p /root/yaml/CoreAddons/network-plugin/{kube-flannel,calico} |
kube-flannel
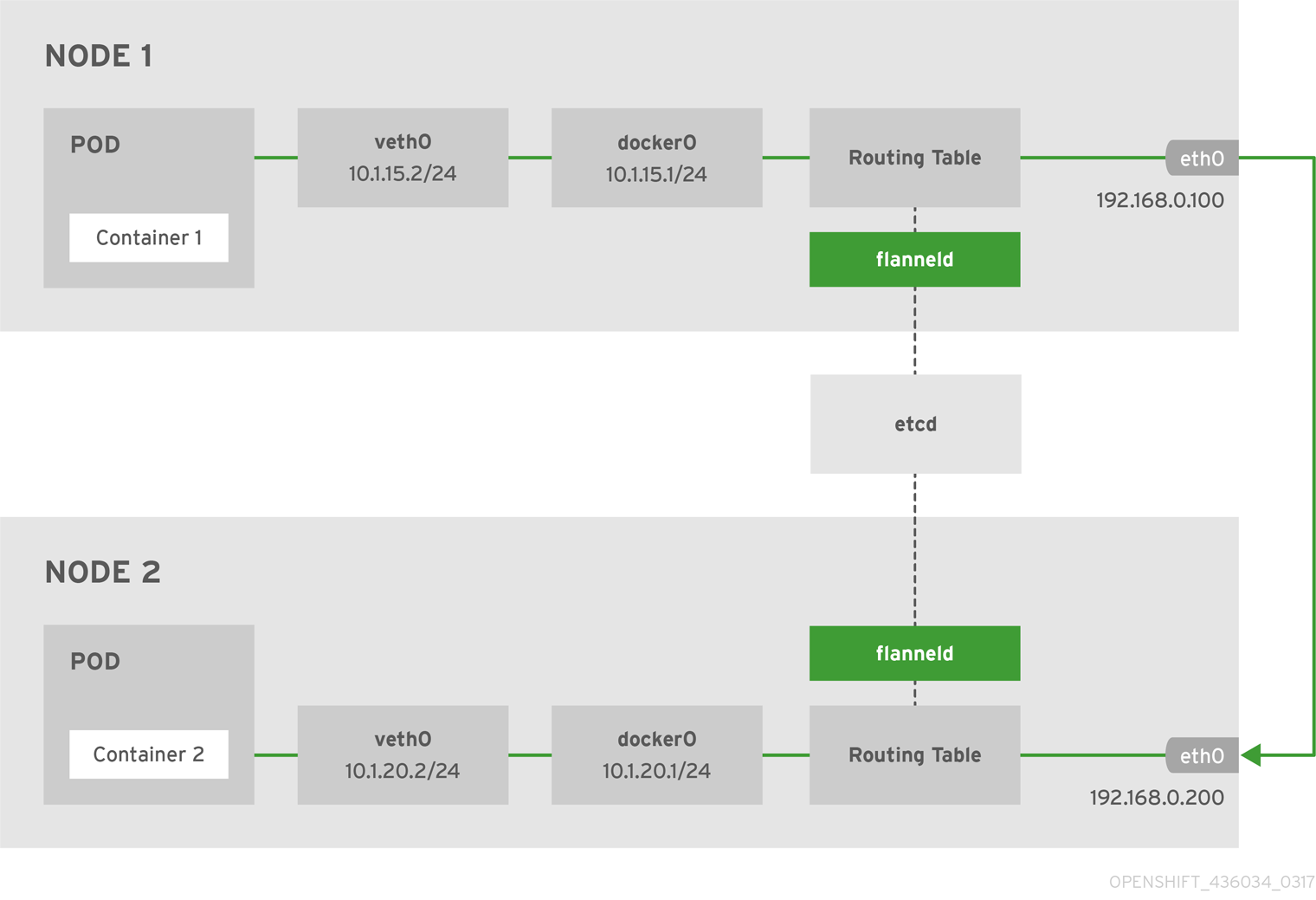
说明
- kube-flannel基于VXLAN的方式创建容器二层网络,使用端口
8472/UDP通信 - flannel 第一次启动时,从 etcd 获取 Pod 网段信息,为本节点分配一个未使用的 /24 段地址,然后创建 flannel.1(也可能是其它名称,如 flannel1 等) 接口。
- 官方提供yaml文件部署为
DeamonSet - 若需要使用
NetworkPolicy功能,可以关注这个项目canal
架构图
切换工作目录
1 | cd /root/yaml/CoreAddons/network-plugin/kube-flannel |
下载yaml文件
1 | wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml |
官方yaml文件包含多个平台的daemonset,包括amd64、arm64、arm、ppc64le、s390x
这里以amd64作为例子,其他的可以自行根据需要修改或者直接删除不需要的daemonset
官方yaml文件已经配置好容器网络为
10.244.0.0/16,这里需要跟kube-controller-manager.conf里面的--cluster-cidr匹配如果在
kube-controller-manager.conf里面把--cluster-cidr改成了其他地址段,例如192.168.0.0/16,用以下命令替换kube-flannel.yaml相应的字段
1 | sed -e 's,"Network": "10.244.0.0/16","Network": "192.168.0.0/16," -i kube-flannel.yml |
如果服务器有多个网卡,需要指定网卡用于flannel通信,以网卡ens33为例
- 在
args下面添加一行- --iface=ens33
- 在
1 | containers: |
修改backend
- flannel支持多种后端实现,可选值为
VXLAN、host-gw、UDP - 从性能上,
host-gw是最好的,VXLAN和UDP次之 - 默认值是
VXLAN,这里以修改为host-gw为例,位置大概在75行左右
1 | net-conf.json: | |
部署kube-flannel
1 | kubectl apply -f kube-flannel.yml |
检查部署情况
1 | kubectl -n kube-system get pod -l app=flannel |
输出示例
1 | NAME READY STATUS RESTARTS AGE |
- 如果等很久都没Running,可能是你所在的网络环境访问quay.io速度太慢了
- 可以替换一下镜像,重新apply
1 | sed -e 's,quay.io/coreos/,zhangguanzhang/quay.io.coreos.,g' -i kube-flannel.yml |
Calico
说明
- Calico 是一款纯 Layer 3 的网络,节点之间基于BGP协议来通信。
- 这里以
calico-v3.7.0来作为示例 - 部署文档
架构图

切换工作目录
1 | cd /root/yaml/CoreAddons/network-plugin/calico |
下载yaml文件
- 这里选用的是【
Installing with the Kubernetes API datastore—50 nodes or less】
1 | wget https://docs.projectcalico.org/v3.7/manifests/calico.yaml |
修改YAML文件
calico-node服务的主要参数如下
CALICO_IPV4POOL_CIDR配置Calico IPAM的IP地址池,默认是192.168.0.0/16
1 | # The default IPv4 pool to create on startup if none exists. Pod IPs will be |
CALICO_IPV4POOL_IPIP配置是否使用IPIP模式,默认是打开的
1 | # Enable IPIP |
部署Calico
1 | kubectl apply -f /root/yaml/CoreAddons/network-plugin/calico/ |
检查部署情况
- 检查calico-node
1 | kubectl -n kube-system get pod -l k8s-app=calico-node |
输出示例
1 | NAME READY STATUS RESTARTS AGE |
检查节点状态
网络组件部署完成之后,可以看到node状态已经为
Ready
1 | kubectl get node |
服务发现组件部署
- kubernetes从v1.11之后,已经使用CoreDNS取代原来的KUBE DNS作为服务发现的组件
- CoreDNS 是由 CNCF 维护的开源 DNS 方案,前身是 SkyDNS
- 配置文件以kubeadm生成的YAML文件作为模板,再添加额外配置
创建工作目录
1 | mkdir -p /root/yaml/CoreAddons/coredns |
切换工作目录
1 | cd /root/yaml/CoreAddons/coredns |
CoreDNS
创建yaml文件
ServiceAccount
1 | cat > /root/yaml/CoreAddons/coredns/coredns-sa.yaml <<EOF |
ConfigMap
1 | cat > /root/yaml/CoreAddons/coredns/coredns-cm.yaml <<EOF |
RBAC
1 | cat > /root/yaml/CoreAddons/coredns/coredns-rbac.yaml <<EOF |
Deployment
1 | cat > /root/yaml/CoreAddons/coredns/coredns-dp.yaml <<EOF |
Service
1 | cat > /root/yaml/CoreAddons/coredns/coredns-svc.yaml <<EOF |
修改yaml文件
- yaml文件里面定义了
clusterIP这里需要与kubelet.config.file里面定义的cluster-dns一致 - 如果kubelet.conf里面的
--cluster-dns改成别的,例如x.x.x.x,这里也要做相应变动,不然Pod找不到DNS,无法正常工作 - 这里定义静态的hosts解析,这样Pod可以通过hostname来访问到各节点主机
- 用下面的命令根据
HostArray的信息生成静态的hosts解析
1 | sed -e '16r '<(\ |
- 上面的命令的作用是,通过
HostArray的信息生成hosts解析配置,顺序是打乱的,可以手工调整顺序 - 也可以手动修改
coredns.yaml文件来添加对应字段
1 | apiVersion: v1 |
部署CoreDNS
1 | kubectl apply -f /root/yaml/CoreAddons/coredns/ |
检查部署状态
1 | kubectl -n kube-system get pod -l k8s-app=kube-dns |
输出样例
1 | NAME READY STATUS RESTARTS AGE |
验证集群DNS服务
- 创建一个deployment测试DNS解析
1 | cat > /root/yaml/busybox-deployment.yaml <<EOF |
- 检查deployment部署情况
1 | kubectl get pod |
- 验证集群DNS解析
- 上一个命令获取到pod名字为
busybox-7b9bfb5658-872gj - 通过kubectl命令连接到Pod运行
nslookup命令测试使用域名来访问kube-apiserver和各节点主机
1 | echo "--- 通过CoreDNS访问kubernetes ---" |
Metrics Server
- Metrics Server
是实现了 Metrics API 的元件,其目标是取代 Heapster 作位 Pod 与 Node 提供资源的 Usage
metrics,该元件会从每个 Kubernetes 节点上的 Kubelet 所公开的 Summary API 中收集 Metrics - Horizontal Pod Autoscaler(HPA)控制器用于实现基于CPU使用率进行自动Pod伸缩的功能。
- HPA控制器基于Master的kube-controller-manager服务启动参数–horizontal-pod-autoscaler-sync-period定义是时长(默认30秒),周期性监控目标Pod的CPU使用率,并在满足条件时对ReplicationController或Deployment中的Pod副本数进行调整,以符合用户定义的平均Pod
CPU使用率。 - 在新版本的kubernetes中 Pod CPU使用率不在来源于heapster,而是来自于metrics-server
- 官网原话是 The –horizontal-pod-autoscaler-use-rest-clients is true or unset. Setting this to false switches to Heapster-based autoscaling, which is deprecated.
额外参数
- 设置kube-apiserver参数,这里在配置kube-apiserver阶段已经加进去了
- front-proxy证书,在证书生成阶段已经完成且已分发
1 | --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem |
创建工作目录
1 | mkdir -p /root/yaml/CoreAddons/metrics-server |
切换工作目录
1 | cd /root/yaml/CoreAddons/metrics-server |
下载yaml文件
1 | wget https://raw.githubusercontent.com/kubernetes/kubernetes/v1.14.3/cluster/addons/metrics-server/auth-delegator.yaml |
修改metrics-server-deployment
修改镜像地址
修改metrics-server启动参数
1 | containers: |
修改resource-reader
- 默认配置的权限无法获取node节点信息,会提示
403 Forbidden - 需要在
ClusterRole里面的rules[0].resources增加nodes/stats
1 | apiVersion: rbac.authorization.k8s.io/v1 |
部署metrics-server
1 | kubectl apply -f . |
查看pod状态
1 | kubectl -n kube-system get pod -l k8s-app=metrics-server |
验证metrics
完成后,等待一段时间(约 30s - 1m)收集 Metrics
- 请求metrics api的结果
1 | kubectl get --raw /apis/metrics.k8s.io/v1beta1 |
示例输出
1 | { |
- 获取节点性能数据
1 | kubectl top node |
输出示例
1 | NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% |
- 获取Pod性能数据
1 | kubectl -n kube-system top pod |
输出示例
1 | NAME CPU(cores) MEMORY(bytes) |
#############################################################################
Kubernetes集群已基本可用
#############################################################################
Kubernetes ExtraAddons
说明
- 下面的部署流程,更多的是补充Kubernetes的能力
- 只记录简单的部署过程,不保证
ctrl+c和ctrl+v能直接跑!
Dashboard
说明
- Dashboard 是kubernetes社区提供的GUI界面,用于图形化管理kubernetes集群,同时可以看到资源报表。
- 官方提供yaml文件直接部署,但是需要更改
image以便国内部署
创建工作目录
1 | mkdir -p /root/yaml/ExtraAddons/kubernetes-dashboard |
切换工作目录
1 | cd /root/yaml/ExtraAddons/kubernetes-dashboard |
获取yaml文件
1 | wget https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml |
修改镜像地址
1 | sed -e 's,k8s.gcr.io/kubernetes-dashboard-amd64,gcrxio/kubernetes-dashboard-amd64,g' -i kubernetes-dashboard.yaml |
创建kubernetes-Dashboard
1 | kubectl apply -f /root/yaml/ExtraAddons/kubernetes-dashboard/kubernetes-dashboard.yaml |
创建ServiceAccount RBAC
- 官方的yaml文件,ServiceAccount绑定的RBAC权限很低,很多资源无法查看
- 需要创建一个用于管理全局的ServiceAccount
1 | cat<<EOF | kubectl apply -f - |
获取ServiceAccount的Token
1 | kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}') |
查看部署情况
1 | kubectl get all -n kube-system --selector k8s-app=kubernetes-dashboard |
访问Dashboard
- kubernetes-dashborad的svc默认是
clusterIP,需要修改为nodePort才能被外部访问 - 随机分配
NodePort,分配范围由kube-apiserver的--service-node-port-range参数指定
1 | kubectl patch -n kube-system svc kubernetes-dashboard -p '{"spec":{"type":"NodePort"}}' |
- 修改完之后,通过以下命令获取访问kubernetes-Dashboard的端口
1 | kubectl -n kube-system get svc --selector k8s-app=kubernetes-dashboard |
- 可以看到已经将节点的
30216端口暴露出来 IP地址不固定,只要运行了kube-proxy组件,都会在节点上添加
30216端口规则用于转发请求到Pod登录Dashboard,上面已经获取了token,这里只需要把token的值填入输入框,点击
SIGN IN即可登录
Dashboard UI预览图
Ingress Controller
说明
- Ingress 是 Kubernetes 中的一个抽象资源,其功能是通过 Web Server 的 Virtual Host
概念以域名(Domain Name)方式转发到內部 Service,这避免了使用 Service 中的 NodePort 与
LoadBalancer 类型所带來的限制(如 Port 数量上限),而实现 Ingress 功能则是通过 Ingress Controller
来达成,它会负责监听 Kubernetes API 中的 Ingress 与 Service 资源,并在发生资源变化时,根据资源预期的结果来设置 Web Server。 - Ingress Controller 有许多实现可以选择,这里只是列举一小部分
- Ingress NGINX:Kubernetes 官方维护的方案,本次安装使用此方案
- kubernetes-ingress:由nginx社区维护的方案,使用社区版nginx和nginx-plus
- treafik:一款开源的反向代理与负载均衡工具。它最大的优点是能够与常见的微服务系统直接整合,可以实现自动化动态配置
创建工作目录
1 | mkdir -p /root/yaml/ExtraAddons/ingress/ingress-nginx |
切换工作目录
1 | cd /root/yaml/ExtraAddons/ingress/ingress-nginx |
下载yaml文件
1 | wget https://github.com/kubernetes/ingress-nginx/raw/nginx-0.24.1/deploy/mandatory.yaml |
修改镜像地址
如果访问quay.io比较缓慢的话,可以修改一下镜像源
1 | sed -e 's,quay.io/kubernetes-ingress-controller/,zhangguanzhang/quay.io.kubernetes-ingress-controller.,g' \ |
创建ingress-nginx
1 | kubectl apply -f . |
检查部署情况
1 | kubectl -n ingress-nginx get pod |
访问ingress
- 获取ingres的nodeport端口
1 | kubectl -n ingress-nginx get svc |
输出示例
1 | NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE |
- 默认的backend会返回404
1 | curl http://172.16.80.200:32603 |
输出示例
1 | default backend - 404 |
注意
- 这里部署之后,是
deployment,且通过nodePort暴露服务 - 也可以修改yaml文件,将
Ingress-nginx部署为DaemonSet- 使用
labels和nodeSelector来指定运行ingress-nginx的节点 - 使用
hostNetwork=true来共享主机网络命名空间,或者使用hostPort指定主机端口映射 - 如果使用
hostNetwork共享宿主机网络栈或者hostPort映射宿主机端口,记得要看看有没有端口冲突,否则无法启动 - 修改监听端口可以在
ingress-nginx启动命令中添加--http-port=8180和--https-port=8543,还有下面的端口定义也相应变更即可
- 使用
创建kubernetes-Dashboard的Ingress
- kubernetes-Dashboard默认是开启了HTTPS访问的
- ingress-nginx需要以HTTPS的方式反向代理kubernetes-Dashboard
- 以HTTP方式访问kubernetes-Dashboard的时候会被重定向到HTTPS
- 需要创建HTTPS证书,用于访问ingress-nginx的HTTPS端口
创建HTTPS证书
- 这里的
CN=域名/O=域名需要跟后面的ingress主机名匹配
1 | openssl req -x509 \ |
创建secret对象
- 这里将HTTPS证书创建为kubernetes的secret对象
dashboard-tls - ingress创建的时候需要加载这个作为HTTPS证书
1 | kubectl -n kube-system create secret tls dashboard-tls --key ./tls.key --cert ./tls.crt |
创建dashboard-ingress.yaml
1 | apiVersion: extensions/v1beta1 |
创建ingress
1 | kubectl apply -f dashboard-ingress.yaml |
检查ingress
1 | kubectl -n kube-system get ingress |
访问kubernetes-Dashboard
- 修改主机hosts静态域名解析,以本文为例在hosts文件里添加
172.16.80.200 dashboard.k8s.local - 使用
https://dashboard.k8s.local:30083访问kubernetesDashboard了 - 添加了TLS之后,访问HTTP会被跳转到HTTPS端口,这里比较坑爹,没法自定义跳转HTTPS的端口
- 此处使用的是自签名证书,浏览器会提示不安全,请忽略
- 建议搭配
external-DNS和LoadBalancer一起食用,效果更佳
效果图
Helm
- Helm是一个kubernetes应用的包管理工具,用来管理charts——预先配置好的安装包资源,有点类似于Ubuntu的APT和CentOS中的yum。
- Helm chart是用来封装kubernetes原生应用程序的yaml文件,可以在你部署应用的时候自定义应用程序的一些metadata,便与应用程序的分发。
- Helm和charts的主要作用:
- 应用程序封装
- 版本管理
- 依赖检查
- 便于应用程序分发
环境要求
- kubernetes v1.6及以上的版本,启用RBAC
- 集群可以访问到chart仓库
- helm客户端主机能访问kubernetes集群
安装Helm
安装方式二选一,需要科学上网
直接脚本安装
1 | curl -L https://git.io/get_helm.sh | bash |
下载二进制文件安装
1 | wget -O - https://get.helm.sh/helm-v2.14.1-linux-amd64.tar.gz | tar xz linux-amd64/helm |
创建RBAC规则
1 | cat << EOF | kubectl apply -f - |
安装服务端
- helm官方charts仓库 https://kubernetes-charts.storage.googleapis.com/ 需要翻墙访问
- 这里指定了helm的stable repo国内镜像地址,使用的是微软Azure的源
- 具体说明请看这里
1 | helm init --tiller-image gcrxio/tiller:v2.14.1 \ |
检查安装情况
查看Pod状态
1 | kubectl -n kube-system get pod -l app=helm,name=tiller |
输出示例
1 | NAME READY STATUS RESTARTS AGE |
查看helm版本
1 | helm version |
输出示例
1 | Client: &version.Version{SemVer:"v2.14.1", GitCommit:"d325d2a9c179b33af1a024cdb5a4472b6288016a", GitTreeState:"clean"} |
本文至此结束
说明
在【二进制部署 kubernetes v1.11.x 高可用集群】里面对于ExtraAddons有额外的一些内容,例如Rook、Prometheus-Operator、ExternalDNS、EFK等等重新做整理适配实在是太麻烦了。后面再考虑另起文章专门来记录这些内容。